

Part 1 | Part 2 | Part 3 | Part 4 |
At the moment, real-time collaboration is one of the hottest topics in the content management space. After all, one of the key features still absent from many content management systems (CMS) is shared editing among multiple users that successfully handles a variety of conditions. Applications like Google Docs, for instance, leverage a centralized server that manages all operations, but emerging frameworks, Yjs the most prominent among them, are challenging this paradigm with peer-to-peer approaches instead.
Recently, as part of our biweekly Tag1 Team Talks webinar and podcast series, the creator of Yjs, Kevin Jahns (Real-Time Collaboration Systems Lead at Tag1), joined Fabian Franz (Senior Technical Architect and Performance Lead at Tag1), Michael Meyers (Managing Director at Tag1), and yours truly (Preston So, Editor in Chief at Tag1 and author of Decoupled Drupal in Practice) for a deep dive into how Yjs and its unique approaches make real-time collaboration in a peer-to-peer manner more efficient than foregoing paradigms for shared editing.
In this multi-part blog series, we explore Yjs’s inner workings, how it came to be, and why it is far and away the best solution for real-time collaborative editing. For this first installment, we cover some of the background behind Yjs and why peer-to-peer approaches for collaborative editing are more advantageous than the traditional server-based paradigm.
Before we begin: Defining a few terms
Traditional approaches to real-time collaborative editing leverage operational transformation (OT), which handles document state, consistency maintenance, and concurrency control in addition to a variety of other features such as conflict resolution and group-awareness.
Meanwhile, in distributed approaches such as peer-to-peer shared editing, conflict-free replicated data types (CRDT) improve on the performance of central servers by propagating state only through transmissions of update operations. In this approach, replicas receiving the updates apply the indicated operations locally.
How Yjs got started
As part of our webinar together, Kevin shared with us some of the story behind how he became interested in real-time collaboration. In 2013, Kevin was at the Institute for Databases and Information Systems at Aachen University, where he was working on a software development kit (SDK) that was a close clone of Google Wave. At the time, Google Wave was a novel approach to how real-time collaboration could work.
One could create and design spaces that were collaborative by default, with the ability to add widgets to a collaborative space. For instance, a user could add a widget for reading e-mails to a space as well as a note-taking widget on the side, both of which were collaborative off the shelf. Other users on a group account would then be able to read e-mails and take notes on those same widgets collaboratively. In short, Google Wave was unique in that it was collaborative by default.
Peer-to-peer by default
Though Wave was eventually discontinued, Kevin’s project in Aachen was a similar approach, with the added advantage that those same widgets could communicate with one another. In Google Wave, on the other hand, all collaborative widgets communicated with a centralized server, which would be responsible for coordinating all operations and synchronizing everything back to the widgets on users’ devices. In Kevin’s SDK, however, everything was peer-to-peer by default without any notion of a server.
To illustrate this, let’s use an example. A widget could send a message on a particular topic while other widgets listened to that topic. Messages would propagate through to other widgets through a mixture of the XMPP protocol, a multi-user chatroom, and a special browser communication layer, all of which was easily adapted to using WebRTC. Kevin recalls a colleague connecting a Mario GameBoy game to one widget while controls were on another widget. In doing so, he could control Mario using a controller on a wholly separate computer through peer-to-peer collaboration.
The key question Kevin wanted to answer through his bachelor’s thesis was: Why doesn’t operational transformation work well in a peer-to-peer manner? Because the main application of his Wave-like SDK was state sharing, he wanted to write it in a way where one could share any arbitrary state across devices through a framework for peer-to-peer collaboration.
How shared editing works in operational transformation
Operational transformation can be relatively straightforward to illustrate. Consider the following timeline diagram, in which two users wish to perform an operation.
![]()
In operational transformation (OT), we represent operations that occur in a timeline. In this scenario, User 1 wishes to insert character “A” at position 0, indicated by (“A”, 0). She then sends this operation to the other user, User 2. At the same time, User 2 inserts character “B” at position 0, indicated by (“B”, 0). She then sends that operation to User 1. This creates a conflict in which both operations are intended to occur simultaneously.
In OT, there are two possible outcomes here: either we end up with a document “AB” or a document “BA”; the transformation is simple because we compare the operations using user identifiers. Because User 1’s operation was created by a user whose identifier takes precedence over User 2’s, User 1’s operation takes precedence over User 2’s operation. And because 2 is higher than 1, we insert B to the right of A, and the result is document “AB”. As for User 2’s operation, becauses 1 is smaller than 2, her operation takes precedence in User 2’s view, so User 2 therefore also sees a result of document “AB”.
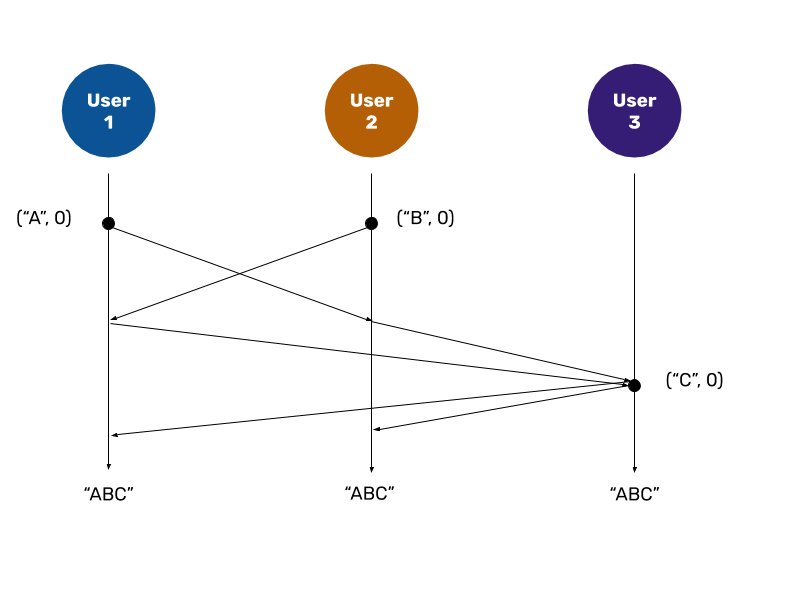
Operational transformation can also be successful across three users, as you can see in the timeline diagram above, but the correct algorithm needs to be applied in a peer-to-peer context. For instance, when User 1’s and User 2’s operations are registered by User 3, this means that both User 1’s and User 2’s operations are distributed to User 3.
Thus, when User 3 inserts “C” at position 0, indicated by (“C”, 0), he propagates that operation to the other clients. These clients are aware that User 3’s operation is no longer concurrent to the other operations, so they do not need to transform it. The peers only need to resolve which operations are concurrent to one another and perform transformation thereafter. This sums up the general idea behind transformation by position.
Why peer-to-peer is better than a central server
The above description illustrates why peer-to-peer approaches are more efficient than a traditional server-based approach. Though operational transformation can function peer-to-peer, the advantage of using CRDTs is that all operations defined are idempotent and commutative by default.
They are idempotent in that no matter how many times you apply the same operation, you will have the same result. In other words, you can apply the same operation twice, and nothing will happen on the second occurrence of the operation. The operations are commutative in that the sequence in which the operations are applied do not have any bearing on the result of the operations as a whole.
Conclusion
As you can see, some of the most important features of Yjs originated due to creator Kevin Jahns’ background in working on real-time collaboration solutions. Yjs’s peer-to-peer approach was directly influenced by some of the disadvantages seen in traditional perspectives on operational transformation and central servers mediating operations. By leveraging CRDTs, we can leverage key benefits such as idempotence and commutativity to ensure that operations are efficient.
In the second installment of this blog series, we dive into the key features of Yjs and why it succeeds in satisfying real-time collaboration use cases in a peer-to-peer manner and without a central server. In doing so, we’ll cover the Yjs algorithm and Yjs performance, digging deeply into CRDTs, concatenation of operations, deletions, and how operations are defined. Then, we’ll inspect some edge cases consisting of large operations to test our assumptions about the advantages of Yjs.
Special thanks to Fabian Franz, Kevin Jahns, and Michael Meyers for their feedback during the writing process.
For more Yjs content, see Yjs - Add real-time collaboration to any application.
Part 1| Part 2 | Part 3 | Part 4 |
Photo by Sapan Patel on Unsplash