

Part 1 | Part 2 | Part 3 | Part 4 |
Table of Contents
- How Yjs works
- The Yjs algorithm
- Achieving performant document operations
- CRDTs and text editor usability
- Concatenating operations
- Deletions
- Defining operations
- Large operations with efficient encoding
- Conclusion
In the previous blog post in this multi-part series about Yjs, we discussed the history and origins of Yjs, directly from its creator Kevin Jahns, as well as operational transformation (OT) and some of the advantages that peer-to-peer approaches to real-time collaboration have over the use of a centralized server. Tag1 recently selected Yjs as its shared editing framework of choice, pairing it with ProseMirror for a top Fortune 50 company.
Recently, I (Preston So, Editor in Chief at Tag1 and author of Decoupled Drupal in Practice) had the opportunity to sit down with Kevin Jahns (Real-Time Collaboration Systems Lead at Tag1 and creator of Yjs), Fabian Franz (Senior Technical Architect and Performance Lead at Tag1), and Michael Meyers (Managing Editor at Tag1) for an exploration of some of the most fascinating components and ideas behind Yjs. In this blog post, we cover how Yjs works, the Yjs algorithm, and how Yjs makes real-time collaboration more efficient through certain performance enhancements and low-level features.
How Yjs works
Before proceeding, I strongly recommend that you read the first installment in this blog series, as content hereafter assumes knowledge presented in the previous post.
To illustrate how Yjs works, we must consider that in CRDTs, the concurrency model is different. Kevin’s first attempt to resolve the peer-to-peer problem was through operational transformation. After all, in Google Docs and other OT implementations, there is always a central server handling and performing the transformations. As soon as a central server is available, there is now a single point where decisions can be made about how the resulting document should look.
In this way, the problem of concurrency becomes much easier due to centrality. With a central server, you no longer need to think about cases in which users need to send operations to other users, as their respective operations are juggled and mediated by a central server, which can determine a global order of operations. Such a central server also serves as a finite state machine in lieu of a complex mix of users performing operations.
The Yjs algorithm
Consider the following diagram, which illustrates how the Yjs algorithm works.
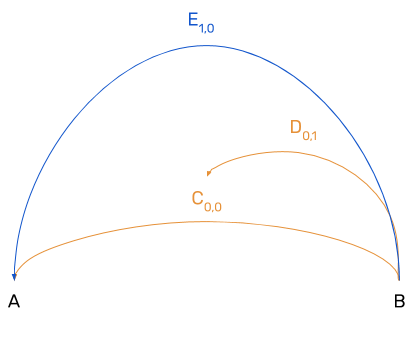
In creating Yjs, Kevin created an algorithm that presents a visual model of the concurrency model necessary in order to provide for peer-to-peer shared editing using CRDTs. Consider a situation in which we start with the document “AB”, and another user wishes to insert “C” between “A” and “B”. In Yjs, every character is assigned a unique identifier (which internally is known as a timestamp, but solely in the sense of position of time rather than a Unix timestamp or the like).
The timestamp is defined through a pair of integers, similar to coordinates: first is the _user identifier_, the user who performed the operation, and second comes an ever-incrementing clock, which indicates where in the sequence of operations the operation occurs. For instance, the following timestamp indicates that user 0 has executed an operation with the clock 0:
C0,0Now that we have these coordinates, we can now insert “D” in between “B” and “C” using the following operation, which shows that the same user is performing another insertion:
D0,1
Consider now that another user wishes to insert “E” between “A” and “B”, but this operation is concurrent with the earlier insertion of “C” (C0,0). The user’s identifier is different, but the clock is identical to the earlier insertion:
E1,0
Because there is a concurrency conflict, Yjs performs the same conflict resolution as OT and compares the user identifiers of the respective insertions. Because user identifier 1 is greater than 0, the resulting document is:
ACDEB
As you can see, this is very much the same principle as OT, but this approach leverages a different visual representation of how characters are inserted into the document. Rather than using absolute positions, as many other approaches do, we use identifiers, because in Yjs, all individual characters are assigned unique identifiers.
Achieving performant document operations
When it comes to large documents having many characters, performance becomes a key consideration for peer-to-peer collaborative editing. After all, peer-to-peer approaches lack a central server to ensure that operations are handled in a performant manner.
CRDTs and text editor usability
One of the key issues in CRDTs is whether they are usable for text editors given the many characters editors typically handle. Consider, for example, a book with 100,000 characters. As we saw in the previous section, Yjs assigns a unique identifier to each character, and each character also has an object attached to it. This seems like a performance nightmare given the number of characters we need to juggle.
Kevin has worked with the v8 team and other JavaScript engine maintainers in order to optimize Yjs’ performance to ensure that objects are represented efficiently in memory, so that we can suitably handle the vast number of characters that documents inevitably contain. Instead of using objects for each individual character, for instance, we can define these objects in such a way that JavaScript will represent this similarly to a struct in the C programming language. This is far more efficient than defining every character as a hash table, which would be overkill for what we need in this case.
In the following section, we dive into how Yjs defines operations to illustrate this.
Concatenating operations
Earlier in this post, we saw that each character is uniquely identified by a covector, as we see in the following operation:A0,0
Most users perform sequential insertions. To type the string “ABC”, most users will type “A” followed by “B”, etc., leading to the following sequence of operations. Recall that the first integer indicates the user identifier, and the second indicates the clock:
A0,0 B0,1 C0,2
When users insert a large quantity of content, this is how such sequential insertions will always be represented. The clock will always increment by 1 with every operation executed. But this is terribly inefficient and will not perform well at scale. Instead, we can define a third coordinate for length, which describes the number of child operations contained in the operation. Consider the following operation, whose result will be identical to the immediately preceding example:
ABC0,0,3
This is how Yjs handles text objects within JavaScript. The framework concatenates the objects such that we now have many character insertions defined together as a single operation. By using this approach, Yjs limits the footprint on the database where document updates are stored.
Deletions
However, the most important downside to this approach is that addressing individual characters becomes more complex. When another user wishes to insert a character between “B” and “C”, the “BC” portion of the operation needs to be split into two separate operations. We cannot recombine these operations, because in CRDTs we can never delete characters or remove them from the document tree.The only way in which we can indicate that a character needs to be removed is by marking it deleted. To explain this, let’s turn to the approach undertaken by ProseMirror, a rich text editor, which Tag1 selected during its evaluation of rich text editors for a top Fortune 50 company. In ProseMirror, there is a distinction between paragraph nodes and text nodes. When you mark a paragraph as deleted, you can mark all of the constituent text structs deleted as well.
In short, the following paragraph, containing "ABC", when marked deleted:
(Paragraph)D
is equivalent to marking all of the following text nodes (characters) deleted as well:
AD BD CD
As a result, we can now remove all of these operations from memory entirely, because the character nodes are children of paragraphs that were deleted.
Defining operations
In Yjs, operations have the following structure, here shown in pseudo-JSON:
{
id
left
right
deleted
content
}
where id is the identifier for the operation, left is the identifier of the object to the left, right is the identifier of the object to the right, deleted indicates the deletion state — whether the object has been deleted or not — and content represents the content to be inserted in an insertion operation, for example.
If we never add anything to this object, compilers can deduce that objects are always organized in this fashion. Therefore, we can store the entire object as a struct in memory, thus avoiding the use of hash tables, which is how objects are typically stored in JavaScript. In turn, by optimizing objects as structs, JavaScript will use comparatively little browser or Node.js memory when handling operations.
Because we can still address a deleted character with this approach, concurrency is a solved problem. We simply mark a character as deleted in the object, but the complete information about the character remains available in the internal format. Yjs does not display this to the user, but we still require deleted characters in memory to handle concurrency.
Large operations with efficient encoding
One of the key questions evaluators have about Yjs is performance when it comes to large operations. For instance, consider a scenario in which we paste a lengthy Wikipedia article of 100,000 characters. Rather than using the Undo button, we delete the content manually. Thereafter, we paste it again and delete it again without touching the Undo or Redo buttons. An important question to answer is how Yjs handles such operations efficiently such that we do not have dozens of copies of the same content each time this occurs.
In JavaScript, there are two modes, one with garbage collection enabled. When we copy and paste a Wikipedia article, we can delete content through a single operation in which we indicate a very large length (in this case 300,000):
X...0,0,300000D
Another approach that we can employ to make this operation more performant is through efficient encoding techniques. When we send these operations to other peers, they need to be represented as efficiently as possible for performance’s sake. In this scenario, we have 100,000 characters that are not merged or concatenated and are merely single operations. If we send these characters as JSON objects, we would overwhelm our memory buffer, because JSON is an inefficient format for handling objects.
However, if we use binary encoding instead, which represents integers in four bits, we can encode the covector integers much more efficiently. In Yjs, for instance, we can often represent integers in only three bits thanks to variable-length encoding. If we do this in JSON, all integers are transformed into strings, so the only complicating factor is length. This means that a single number could be represented in as little as five bytes.
Conclusion
The Yjs JavaScript module is only ten kilobytes in size and already contains features such as concurrency handling and document update encoding. However, communication over WebRTC, WebSockets, the IPFS network, and XMPP are all features that require additional modules to function. When asked how Yjs users can contribute, Kevin said, “If you’re working on one of those projects or IPFS, I would love to collaborate on a communication module for Yjs.” Editor support for a variety of rich text editors is also on the way. By sharing knowledge and our own experiences using Yjs, especially in product implementations, we can benefit the world of peer-to-peer technology in unprecedented ways. As for Yjs, Kevin is hard at work on Yjs 13.0, which is a full rewrite of Yjs 12.0, and many features are still outstanding for porting to the upcoming version. As for Kevin’s future plans, his interests lie in adding a peer-to-peer network to Yjs where users can share documents, in a similar fashion to BitTorrent. We at Tag1 are excited for the peer-to-peer future of real-time collaboration, and we encourage you to try Yjs today too!
Special thanks to Fabian Franz, Kevin Jahns, and Michael Meyers for their feedback during the writing process.
For all of Tag1's Yjs content, see Yjs - Add real-time collaboration to any application.
Photo by Sapan Patel on UnsplashYou can also revisit Part 1:What is Yjs and operational transformation?